


@davisdavidDavis David
Data Scientist | AI Practitioner | Software Developer. Giving talks, teaching, writing.
The Datasets library from hugging Face provides a very efficient way to load and process NLP datasets from raw files or in-memory data. These NLP datasets have been shared by different research and practitioner communities across the world.
You can also load various evaluation metrics used to check the performance of NLP models on numerous tasks.
If you are working in Natural Language Processing and want an NLP dataset for your next project, I recommend you use this library from Hugging Face.
You can use this library with other popular frameworks in machine learning, such as Numpy, Pandas, Pytorch, and TensorFlow. You will learn more in the examples below.
The NLP datasets are available on different tasks such as
- Text-classification
- Question-Answering
- Sequence-modelling
- Machine translation,
- Automatic speech-recognition
- Sentiment Analysis
- Speech Processing
- Name entity Recognition
- Part of Speech Tagging
- others
You can find the NLP datasets in more than 186 languages. All these datasets can also be browsed on the HuggingFace Hub and can be viewed and explored online with the Datasets viewer.
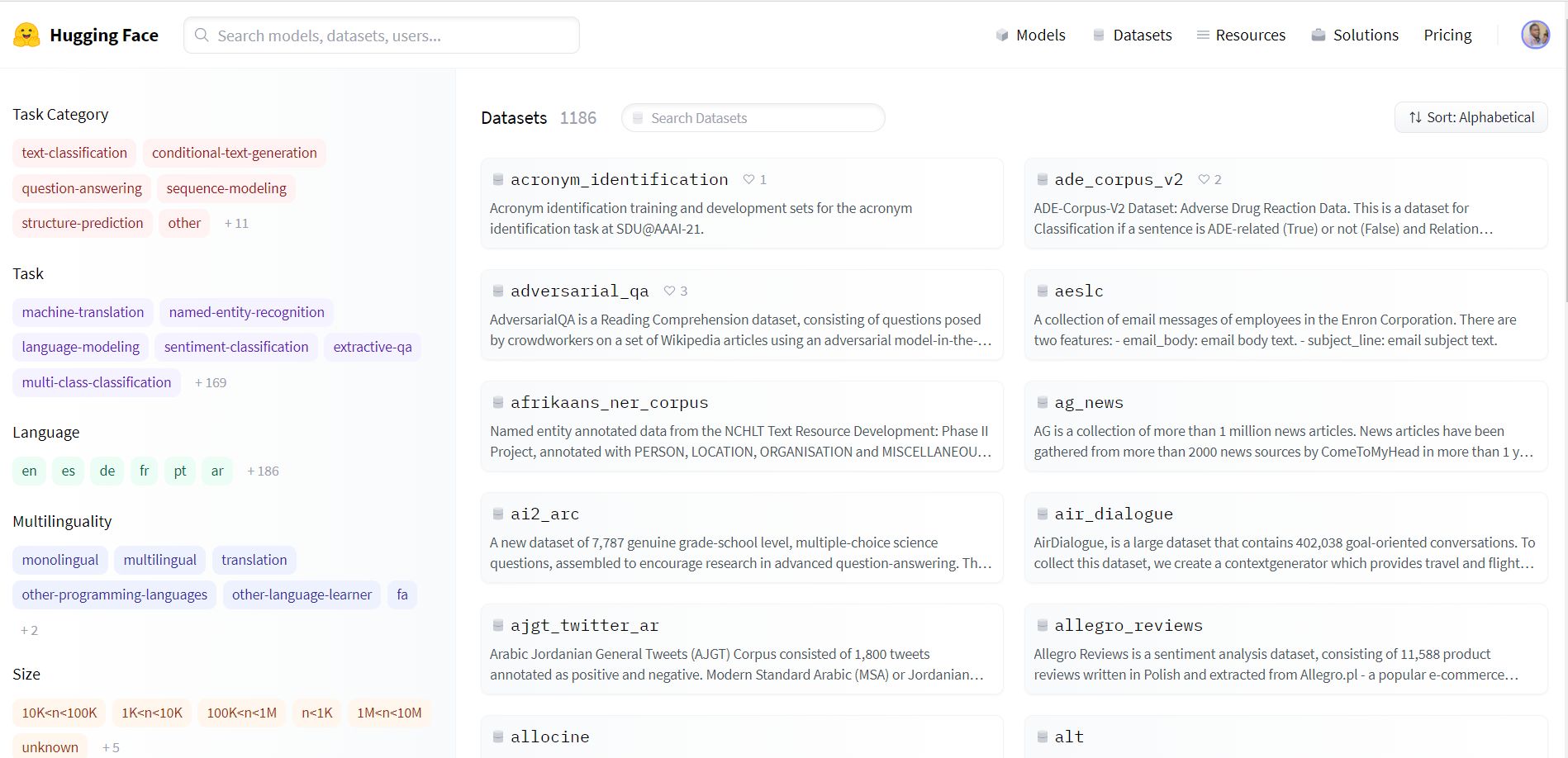
In this article, you will learn how to download, load, configure and use NLP datasets from the hugging face datasets library.
Let's get started.
How to Install Datasets Library
Installation is easy and takes only a few minutes. You can use pip as follows:
pip install datasets Another option for installation is using conda as follows.
conda install -c huggingface -c conda-forge datasetsList of Datasets
To view the list of different available datasets from the library, you can use the
list_datasets()from datasets import list_datasets, load_dataset
from pprint import pprint
datasets_list = list_datasets()
pprint(datasets_list,compact=True)

Currently, the datasets library has a total of 1182 datasets that can be used to create different NLP solutions.
List of Dataset with Details
You can also view a list of the datasets with details by adding an argument called
with_detailsTruedatasets_list = list_datasets(with_details=True)
pprint(datasets_list)
This will show a list of datasets with their id(name), descriptions, and files (if downloaded in your local machine).

Load Dataset
To load the dataset from the library, you need to pass the file name on the
load_dataset()The load_dataset function will do the following.
- Download and import in the library the file processing script from the Hugging Face GitHub repo.
- Run the file script to download the dataset
- Return the dataset as asked by the user. By default, it returns the entire dataset
dataset = load_dataset('ethos','binary') 
In the above example, I downloaded the ethos dataset from hugging face.
"ETHOS: onlinE haTe speecH detectiOn dataSet. This repository contains a dataset for hate speech detection on social media platforms, called Ethos. There are two variations of the dataset:"- HuggingFace's page
Note: Each dataset can have several configurations that define the sub-part of the dataset you can select. For example, the ethos dataset has two configurations.
- binary version
- multi-label version
Let’s load the binary version we have downloaded.
print(dataset)
Split the Train and Validation Sets
Sometimes you don't want to download the entire dataset, you can use the split parameter to specify if you want to download the train, validation, or test set from the dataset.
ethos_train = load_dataset('ethos','binary',split='train')
ethos_validation = load_dataset('ethos','binary',split='validation')This will save the training set in the
ethos_trainethos_validationNote: Not all datasets have the train, validation, and test set. Some of them can contain only the train set. So you need to read more about the dataset you want to download from the hugging face dataset page.
Load Dataset from Local File
You can use the library to load your local dataset from the local machine. You can load datasets that have the following format.
- CSV files
- JSON files
- Text files (read as a line-by-line dataset),
- Pandas pickled dataframe
To load the local file you need to define the format of your dataset (example "CSV") and the path to the local file.
dataset = load_dataset('csv', data_files='my_file.csv')You can similarly instantiate a Dataset object from a pandas DataFrame as follows:
from datasets import Dataset
import pandas as pd
df = pd.DataFrame({"a": [1, 2, 3]})
df_dataset = Dataset.from_pandas(df)
print(df_dataset)
Download Mode
When you load already downloaded data from the cache directory, you can control how the
load_datasets()The parameter options are as follows.
- "reuse_dataset_if_exists" (default) - This will reuse both raw downloads and the prepared dataset if they exist in the cache directory.
- "reuse_cache_if_exists"- This will use the cached dataset.
- "force_redownload" - This will redownload the dataset.
dataset = load_dataset('ethos','binary', download_mode="force_redownload")In the above example, we redownload the ethos dataset with binary configuration.
Setting The Format
You can set the format of the dataset instance by using the
set_format()type: an optional string that defines the type of the objects that should be returned by
datasets.Dataset.getitem()- None/'python' (default): return python objects,
- 'torch'/'pytorch'/'pt': return PyTorch tensors,
- 'tensorflow'/'tf': return Tensorflow tensors,
- 'jax': return JAX arrays,
- 'numpy'/'np': return Numpy arrays,
- 'pandas'/'pd': return Pandas DataFrames
ethos_train.set_format(type='pandas', columns=['comment', 'label'])In the above example, we set the format type as "pandas".
Final Thoughts on NLP Datasets from Huggingface
In this article, you have learned how to download datasets from hugging face datasets library, split into train and validation sets, change the format of the dataset, and more. We did not cover all the functions available from the datasets library. Check the following resources if you are looking to go deeper.
If you learned something new or enjoyed reading this article, please share it so that others can see it. Until then, see you in the next post!
You can also find me on Twitter @Davis_McDavid.
And you can read more articles like this here.
Want to keep up to date with all the latest in Data Science? Subscribe to our newsletter in the footer below.
Tags
Create your free account to unlock your custom reading experience.
You may be interested in:
>> Is a Chromebook worth replacing a Windows laptop?
>> Find out in detail the outstanding features of Google Pixel 4a
>> Top 7 best earbuds you should not miss
Related Posts:
>> Recognizing 12 Basic Body Shapes To Choose Better Clothes
>>Ranking the 10 most used smart technology devices
>> Top 5+ Best E-readers: Compact & Convenient Pen

0 Comments:
Post a Comment